

Are you fascinated by the power of artificial intelligence, but intimidated by the technical jargon surrounding machine learning? Machine learning, a subset of AI, is responsible for everything from recommending your next favorite song on Spotify to powering self-driving cars. But the world of machine learning algorithms can seem complex and overwhelming, especially for beginners. This comprehensive guide will demystify the most common machine learning algorithms, breaking them down into simple terms and providing practical examples to help you understand their applications.
Whether you’re a curious individual seeking to grasp the fundamentals of AI or a budding data scientist looking to expand your toolkit, this guide will equip you with the knowledge necessary to confidently navigate the realm of machine learning. We’ll explore the various types of algorithms, from supervised to unsupervised learning, and delve into their strengths and weaknesses. By the end, you’ll gain a solid understanding of how these algorithms work and how they are transforming the world around us.
What is Machine Learning and How Does it Work?
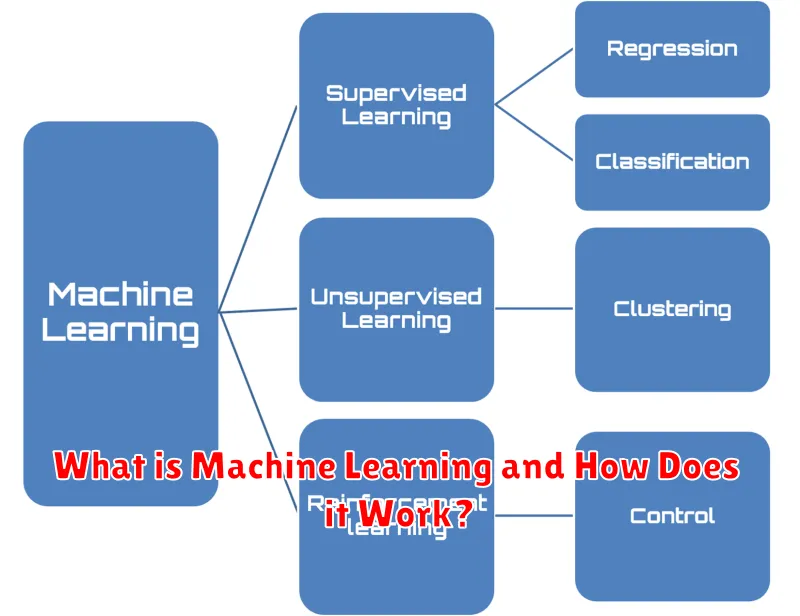
Machine learning (ML) is a type of artificial intelligence (AI) that allows computer systems to learn from data without being explicitly programmed. Instead of relying on a set of predefined rules, ML algorithms identify patterns and insights from data, enabling them to make predictions or decisions.
The core of ML lies in training algorithms on vast amounts of data. This data can be anything from images and text to sensor readings and financial transactions. As the algorithm is exposed to more data, it refines its understanding of the underlying patterns and relationships.
The process of training an ML model involves feeding it data and providing feedback on its performance. This feedback helps the algorithm adjust its parameters, improving its accuracy over time. Once trained, the model can then be used to make predictions on new, unseen data.
Types of Machine Learning: Supervised, Unsupervised, and Reinforcement Learning
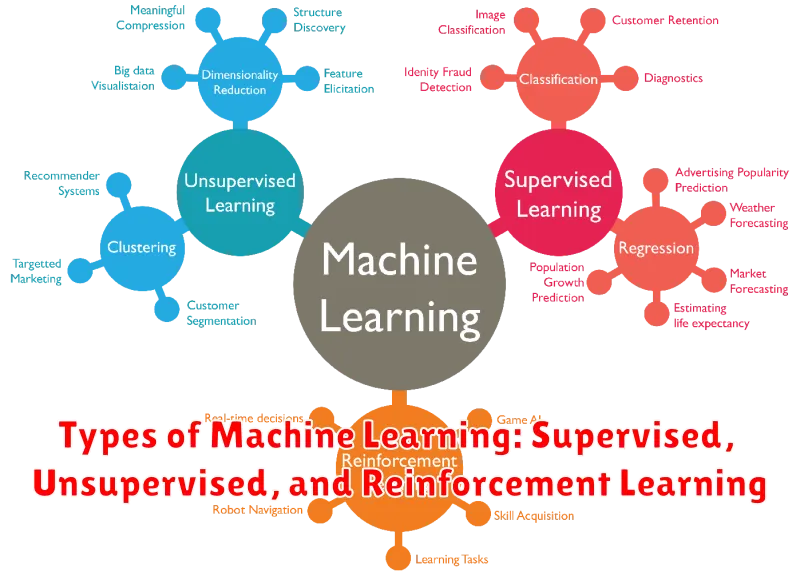
Machine learning, a subfield of artificial intelligence, enables computers to learn from data without explicit programming. At its core, machine learning algorithms analyze data, identify patterns, and make predictions or decisions. But how do these algorithms work, and what are the different types? This article delves into the three primary types of machine learning: supervised learning, unsupervised learning, and reinforcement learning.
Supervised Learning
Imagine a student learning from a teacher who provides labeled examples, explaining the correct answers. This is analogous to supervised learning. In supervised learning, the algorithm is trained on a dataset containing labeled input-output pairs. The algorithm learns the relationship between the inputs and outputs and then uses this knowledge to predict outputs for new, unseen inputs.
Supervised learning algorithms are further classified into two categories: regression and classification.
- Regression predicts continuous values, such as predicting house prices based on features like size, location, and number of bedrooms.
- Classification predicts discrete categories, such as classifying emails as spam or not spam.
Unsupervised Learning
In contrast to supervised learning, unsupervised learning deals with unlabeled data. The algorithm must discover hidden patterns and structures within the data without any prior knowledge.
Unsupervised learning algorithms are commonly used for:
- Clustering: Grouping similar data points together, like segmenting customers based on their purchase history.
- Dimensionality reduction: Simplifying complex data by reducing the number of variables without losing significant information.
Reinforcement Learning
Reinforcement learning is a type of machine learning where the algorithm learns through trial and error. It interacts with an environment, receives feedback in the form of rewards or penalties, and uses this feedback to improve its decision-making process. This approach is inspired by how humans learn, where we try different actions and learn from the consequences.
Reinforcement learning is particularly well-suited for applications like:
- Robotics: Training robots to perform tasks by rewarding them for desired actions and penalizing them for undesired ones.
- Game playing: Developing AI agents that can play games like chess or Go by learning from experience and adapting to their opponent’s strategies.
Conclusion
Each type of machine learning, supervised, unsupervised, and reinforcement, offers unique strengths and serves different purposes. Understanding these fundamental types is crucial for grasping the wide range of applications and possibilities that machine learning presents. Whether it’s predicting outcomes, uncovering hidden patterns, or optimizing actions, machine learning continues to revolutionize various fields, pushing the boundaries of what computers can do.
Common Machine Learning Algorithms: Regression, Classification, Clustering
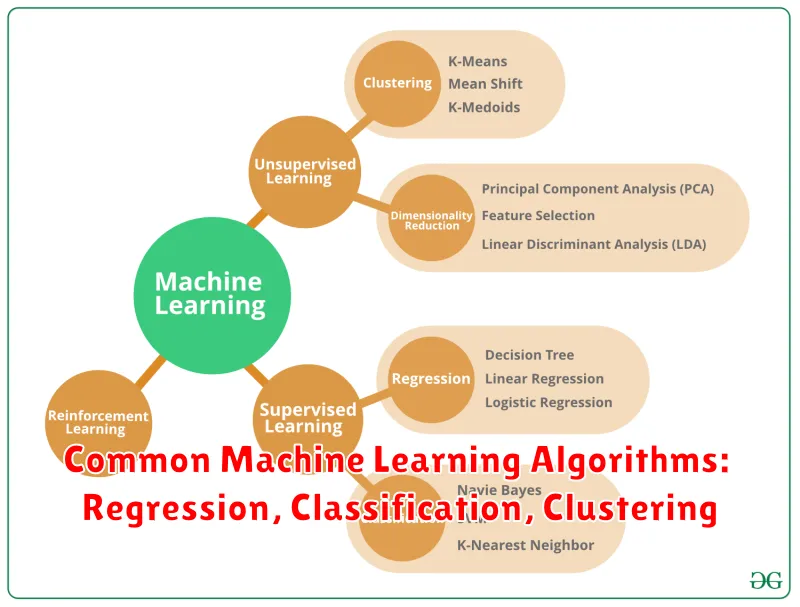
Machine learning is a powerful tool that enables computers to learn from data without being explicitly programmed. It involves a wide range of algorithms, each designed to solve specific tasks. Among the most common and versatile algorithms are those used for regression, classification, and clustering.
Regression
Regression algorithms are used to predict a continuous output variable. They aim to find the relationship between input features and the target variable, allowing us to estimate the value of the target variable for new data.
For example, a regression model could be used to predict the price of a house based on its size, location, and number of bedrooms. Some common regression algorithms include Linear Regression, Polynomial Regression, and Decision Tree Regression.
Classification
Classification algorithms are designed to categorize data into predefined classes or categories. They learn patterns from labeled data and then predict the class of new, unseen data.
Imagine a spam filter that identifies emails as spam or not spam. This is a classic example of classification. Popular classification algorithms include Logistic Regression, Support Vector Machines (SVMs), and Naive Bayes.
Clustering
Clustering algorithms group similar data points together into clusters based on their characteristics. Unlike regression and classification, clustering is an unsupervised learning task, meaning it doesn’t require labeled data. Instead, it finds patterns and structures within the data itself.
For instance, a clustering algorithm could be used to group customers with similar buying habits, helping businesses target their marketing campaigns more effectively. Common clustering algorithms include K-means Clustering, Hierarchical Clustering, and DBSCAN.
Understanding these fundamental machine learning algorithms provides a solid foundation for tackling a wide range of problems. As you delve deeper into the world of machine learning, you’ll discover the intricacies of each algorithm and how to apply them effectively to your specific needs.
Understanding Machine Learning Model Training and Evaluation
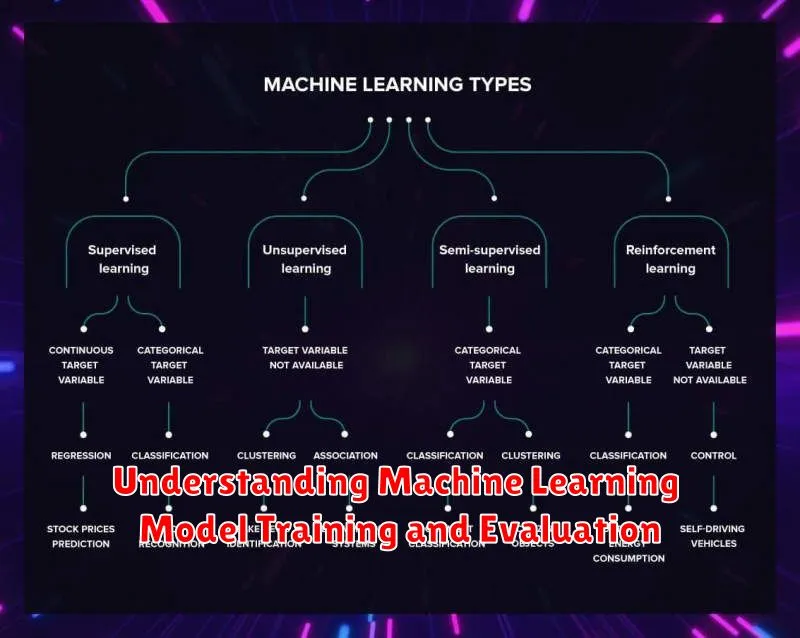
Machine learning models are trained on data to learn patterns and make predictions. The training process involves feeding the model with a dataset and adjusting its internal parameters to minimize errors. This iterative process aims to create a model that can generalize well to unseen data.
Once the model is trained, it’s crucial to evaluate its performance. This involves testing the model on a separate dataset called the “test set.” The evaluation process helps assess how well the model generalizes to new data and identifies potential biases or overfitting.
There are various metrics to evaluate machine learning models, depending on the task. Common metrics include:
- Accuracy: Measures the percentage of correctly classified instances.
- Precision: Measures the proportion of correctly predicted positive instances out of all instances predicted as positive.
- Recall: Measures the proportion of correctly predicted positive instances out of all actual positive instances.
- F1-score: A harmonic mean of precision and recall.
- Mean Squared Error (MSE): Measures the average squared difference between predicted and actual values (for regression tasks).
Understanding the training and evaluation process is crucial for developing effective machine learning models. By carefully selecting training data, evaluating performance using appropriate metrics, and iterating on the model, you can create models that accurately predict and solve real-world problems.
Applications of Machine Learning in Various Industries
Machine learning (ML) is rapidly transforming various industries, revolutionizing the way businesses operate and interact with their customers. From healthcare to finance, e-commerce to manufacturing, ML algorithms are being implemented to automate tasks, improve efficiency, and gain valuable insights from data.
Healthcare
ML is playing a pivotal role in healthcare, enhancing patient care and medical research. Some prominent applications include:
- Disease prediction and diagnosis: ML algorithms can analyze patient data to identify early warning signs of diseases, enabling timely intervention and improving treatment outcomes.
- Personalized medicine: ML can tailor treatment plans based on individual patient characteristics and genetic profiles, optimizing treatment efficacy and minimizing side effects.
- Drug discovery: ML algorithms can accelerate the drug discovery process by analyzing vast datasets of chemical compounds and identifying potential drug candidates.
Finance
In the finance sector, ML is transforming operations, risk management, and customer service. Key applications include:
- Fraud detection: ML algorithms can analyze transaction patterns to identify suspicious activities and prevent financial fraud.
- Credit scoring: ML models can assess creditworthiness based on diverse data points, enabling more accurate credit risk evaluation.
- Algorithmic trading: ML algorithms can analyze market data and execute trades automatically, optimizing investment strategies.
E-commerce
ML is enhancing the customer experience and driving revenue growth in e-commerce. Some notable applications include:
- Recommendation systems: ML algorithms can personalize product recommendations based on user preferences and purchase history, boosting sales and customer satisfaction.
- Dynamic pricing: ML can adjust prices in real-time based on demand, competition, and other factors, maximizing revenue and profitability.
- Customer segmentation: ML algorithms can group customers based on their behavior and preferences, enabling targeted marketing campaigns.
Manufacturing
ML is revolutionizing manufacturing processes, enhancing efficiency and quality control. Some key applications include:
- Predictive maintenance: ML algorithms can analyze sensor data to predict equipment failures, enabling proactive maintenance and reducing downtime.
- Quality control: ML models can inspect products for defects, improving product quality and reducing waste.
- Process optimization: ML algorithms can analyze production data to optimize production processes, reducing costs and improving efficiency.
These are just a few examples of how ML is transforming industries. As ML continues to advance, we can expect to see even more innovative applications across various sectors, shaping the future of business and society.
Choosing the Right Machine Learning Algorithm for Your Problem

Choosing the right machine learning algorithm for your problem is crucial for achieving accurate predictions and successful outcomes. With a vast array of algorithms available, understanding their strengths and weaknesses is essential for making informed decisions. This guide will provide a comprehensive overview of various algorithms, helping you select the most suitable one for your specific needs.
Supervised Learning:
In supervised learning, the algorithm is trained on a dataset with labeled examples, where each example has both input features and the corresponding output label. This allows the algorithm to learn the relationship between input and output, enabling it to predict the output for new, unseen input data. Common supervised learning algorithms include:
- Linear Regression: Used for predicting continuous values, such as house prices or stock prices.
- Logistic Regression: Used for classifying data into distinct categories, such as spam detection or customer churn prediction.
- Decision Trees: Create a tree-like structure to make decisions based on a series of rules.
- Support Vector Machines (SVMs): Find the best hyperplane to separate data points into different classes.
- Naive Bayes: Based on Bayes’ theorem, it calculates the probability of an event based on prior knowledge.
- K-Nearest Neighbors (KNN): Classifies data based on its proximity to known data points.
Unsupervised Learning:
Unsupervised learning algorithms are trained on unlabeled data, aiming to discover patterns and insights without explicit guidance. These algorithms are used for tasks such as clustering, dimensionality reduction, and anomaly detection.
- K-Means Clustering: Groups similar data points together based on their distance from cluster centers.
- Principal Component Analysis (PCA): Reduces the dimensionality of data by finding principal components that capture the most variance.
- DBSCAN: Identifies clusters of varying shapes and densities.
Reinforcement Learning:
Reinforcement learning algorithms learn through trial and error, interacting with an environment to maximize rewards. They are often used for tasks such as game playing, robotics, and recommendation systems.
- Q-Learning: Learns the optimal action to take in a given state to maximize rewards.
- Deep Reinforcement Learning: Combines reinforcement learning with deep neural networks.
Choosing the Right Algorithm:
To choose the right algorithm, consider the following factors:
- Type of problem: Regression, classification, clustering, etc.
- Data characteristics: Size, dimensionality, noise level, etc.
- Performance requirements: Accuracy, speed, scalability.
- Interpretability: Understanding the decision-making process.
Conclusion:
The choice of machine learning algorithm is crucial for achieving successful results. By understanding the strengths and weaknesses of different algorithms, you can make informed decisions and select the most appropriate one for your problem. Remember to consider factors like the type of problem, data characteristics, and performance requirements to ensure optimal performance.
Tools and Technologies for Machine Learning

Machine learning is a powerful tool that can be used to solve a wide range of problems. But to build and deploy machine learning models, you need the right tools and technologies. Here’s a rundown of some of the most popular options, broken down into categories:
Programming Languages
Python is the dominant language for machine learning, thanks to its rich ecosystem of libraries and frameworks. Here are a few key libraries:
- Scikit-learn: A comprehensive library for building machine learning models, including classification, regression, clustering, and more.
- TensorFlow: A powerful library developed by Google for deep learning, suitable for large-scale neural networks.
- PyTorch: Another deep learning library known for its flexibility and ease of use.
While Python is the top choice, other languages like R, Java, and Julia also have their strengths in specific areas of machine learning.
Data Manipulation and Analysis
Working with data is crucial in machine learning. These tools can help:
- Pandas: A Python library for data manipulation and analysis, offering data structures and functions for cleaning, transforming, and exploring data.
- NumPy: Another Python library fundamental for numerical computing and working with arrays and matrices.
- SQL: A language for interacting with relational databases, often used to retrieve and prepare data for machine learning.
Cloud Platforms
Cloud platforms provide infrastructure and services to accelerate machine learning workflows:
- Amazon Web Services (AWS): Offers a wide range of machine learning services, including SageMaker for model building and deployment.
- Google Cloud Platform (GCP): Provides machine learning services like Vertex AI and BigQuery for data warehousing and analysis.
- Microsoft Azure: Offers machine learning services, including Azure Machine Learning Studio for model development and deployment.
Other Tools
Several other tools are crucial in the machine learning process:
- Jupyter Notebook: A popular environment for interactive data exploration and code development.
- Git: A version control system for tracking changes to code and data, facilitating collaboration.
- Visual Studio Code: A versatile code editor with extensions for machine learning development.
The choice of tools depends on your specific needs, project complexity, and comfort level with different technologies. Remember to explore and experiment to find the most effective combination for your machine learning journey.
Challenges and Limitations of Machine Learning

While machine learning has revolutionized many fields, it’s crucial to understand its limitations. Despite its advancements, ML algorithms still face various challenges:
Data Quality and Quantity: Machine learning models are heavily reliant on data. Poor quality, incomplete, or biased data can significantly hinder model performance. Additionally, a substantial amount of data is often required to train complex models effectively.
Overfitting and Underfitting: Overfitting occurs when a model learns the training data too well, failing to generalize to unseen data. Conversely, underfitting happens when a model is too simple and cannot capture the underlying patterns in the data. Balancing these two extremes is critical for model accuracy.
Interpretability and Explainability: Many ML models, especially deep learning models, are considered black boxes, making it difficult to understand their decision-making processes. This lack of interpretability can pose challenges in trust, accountability, and ethical implications.
Computational Resources: Training complex ML models often requires significant computational resources, such as powerful hardware and specialized software. This can be a barrier for individuals or organizations with limited resources.
Evolving Data and Bias: Real-world data constantly evolves, and models trained on past data might become outdated or biased. Regular retraining and monitoring are essential to maintain model accuracy and prevent bias amplification.
Ethical Considerations: The use of ML algorithms raises ethical concerns, such as fairness, privacy, and accountability. It’s crucial to develop and deploy models responsibly, ensuring they do not perpetuate or amplify existing societal biases.
It’s essential to acknowledge these challenges and limitations while leveraging the power of machine learning. As the field continues to evolve, overcoming these hurdles will be key to unlocking its full potential and ensuring responsible and ethical application.
The Future of Machine Learning and Artificial Intelligence

The future of machine learning (ML) and artificial intelligence (AI) is incredibly exciting and promising. As these technologies continue to evolve, they have the potential to revolutionize various industries and aspects of our lives. Here are some key trends that will shape the future of ML and AI:
Increased Automation: AI and ML will continue to automate tasks, making businesses more efficient and productive. This includes automating repetitive tasks, analyzing large datasets, and making predictions based on patterns.
Personalized Experiences: AI will personalize user experiences across various domains, from e-commerce and entertainment to healthcare and education. By analyzing user data and preferences, AI can deliver customized recommendations and services.
Enhanced Decision-Making: AI algorithms will provide valuable insights and support for decision-making processes in various sectors, including finance, healthcare, and government. By analyzing data and identifying patterns, AI can help organizations make informed decisions.
Advancements in Natural Language Processing (NLP): NLP will enable AI systems to understand and respond to human language more naturally. This will revolutionize how we interact with technology, leading to more intuitive and human-like experiences.
Ethical Considerations: As AI becomes increasingly powerful, ethical considerations become paramount. Addressing issues such as bias, privacy, and transparency will be crucial for responsible development and deployment of AI.
The future of ML and AI is full of possibilities. These technologies will continue to evolve rapidly, impacting our lives in profound ways. By understanding the key trends and challenges, we can prepare for a future where AI plays an increasingly vital role in shaping our world.
Getting Started with Machine Learning: Resources and Tips
Machine learning is a powerful tool that can be used to solve a wide range of problems. If you’re interested in getting started with machine learning, there are a few resources and tips that can help you get started.
Online Courses: There are a number of great online courses available that can teach you the basics of machine learning. Some popular options include:
- Coursera’s Machine Learning course by Andrew Ng: This is a highly-rated course that provides a comprehensive introduction to machine learning.
- Stanford’s Machine Learning course: Another excellent option, this course covers a wide range of topics, including supervised and unsupervised learning, deep learning, and reinforcement learning.
- Udacity’s Machine Learning Nanodegree: This program provides a more hands-on approach to learning machine learning, with projects and real-world applications.
Books: There are also a number of books that can help you learn about machine learning. Some popular choices include:
- “Hands-On Machine Learning with Scikit-Learn, Keras & TensorFlow” by Aurélien Géron: A practical guide to machine learning using Python.
- “Introduction to Machine Learning with Python” by Andreas Müller and Sarah Guido: A beginner-friendly introduction to machine learning using Python.
- “The Elements of Statistical Learning” by Trevor Hastie, Robert Tibshirani, and Jerome Friedman: A more advanced book that covers the theory and practice of statistical learning.
Open-source Libraries: Several open-source libraries make it easier to work with machine learning. Some popular libraries include:
- Scikit-learn: A Python library for machine learning that provides a wide range of algorithms and tools.
- TensorFlow: An open-source machine learning platform developed by Google.
- PyTorch: Another popular open-source machine learning library that is known for its flexibility and ease of use.
Tips for Getting Started:
- Start with a specific problem you want to solve: This will help you stay focused and motivated.
- Focus on the fundamentals: It’s important to have a solid understanding of the basic concepts of machine learning before you start working on more complex projects.
- Don’t be afraid to experiment: Machine learning is all about experimentation. Try different algorithms and approaches to see what works best for your problem.
{kind=link}